Effective Stiffness of a Composite Material¶
Introduction¶
This example creates a homogenization linkage to predict the effective stiffness. It starts with a brief background of homogenization theory using the components of the effective elastic stiffness tensor for a composite material. The example uses random microstructures and their average stress values to calibrate the model. It demonstrates the use of Scikit-learn to optimize and fit hyper-parameters. Artificial data is used to calibrate the homogenization pipeline for effective stiffness values and then tested with a test set of microstructures.
Linear Elasticity and Effective Elastic Modulus¶
In this example we create a homogenization linkage that predicts the effective stress component for two-phase microstructures. The boundary conditions in this example are given by,
where \(\bar{\varepsilon}_{xx}\) is the macroscopic strain, \(u\) is the displacement in the \(x\) direction, and \(L\) is the length of the domain. More details about these boundary conditions can be found in [1]. Using these boundary conditions, \(\bar{\sigma}_{xx}\) can be calculated for 6 different types of microstructures given the applied strain, \(\bar{\varepsilon}_{xx}\).
[1]:
import warnings
import dask.array as da
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
import pandas
from sklearn.pipeline import Pipeline
from dask_ml.model_selection import train_test_split
from dask_ml.model_selection import GridSearchCV
from dask_ml.decomposition import IncrementalPCA
from dask_ml.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from pymks import (
solve_fe,
generate_multiphase,
plot_microstructures,
PrimitiveTransformer,
TwoPointCorrelation,
GenericTransformer
)
warnings.filterwarnings('ignore')
[2]:
#PYTEST_VALIDATE_IGNORE_OUTPUT
%matplotlib inline
%load_ext autoreload
%autoreload 2
Data Generation¶
A set of periodic microstructures and their volume averaged elastic stress values \(\bar{\sigma}_{xx}\) are generated using the multiphase microstructure generator and the built in FE stress solver. The generate_multiphase function takes a domain shape, a volume_fraction for each phase, a chunks size for parallel computation and a grain_size argument. The grain_size is a rough estimate for the desired microstructure feature size.
The following code generates six different types of microstructures each with 200 samples with spatial dimensions of 21 x 21. Each of the six samples will have a different microstructure feature size.
Note (bug or issue)¶
The microstructures required shuffling to ensure different classed of microstructure appear in each Dask array chunk. The reason for this is not fully understood currently and requires further investigation.
[3]:
def shuffle(data):
tmp = np.array(data)
np.random.shuffle(tmp)
return da.from_array(tmp, chunks=data.chunks)
[4]:
da.random.seed(10)
np.random.seed(10)
tmp = [
generate_multiphase(shape=(200, 21, 21), grain_size=x, volume_fraction=(0.5, 0.5), chunks=200, percent_variance=0.15)
for x in [(15, 2), (2, 15), (7, 7), (9, 3), (3, 9), (2, 2)]
]
x_data = shuffle(da.concatenate(tmp))
Next the average stress field, \(\bar{\sigma}_{xx}\), for each sample is calculated.
[5]:
y_stress = solve_fe(x_data,
elastic_modulus=(270, 200),
poissons_ratio=(0.28, 0.3),
macro_strain=0.001)['stress'][..., 0]
y_data = da.average(y_stress.reshape(y_stress.shape[0], -1), axis=1).persist()
Dask is inherently lazy so does not compute until required. In this case the data is slow to generate so is computed and then stored in RAM using persist (see Dask Best Practices for more details). This avoids recomputing the sample data every time the machine learning pipeline is executed below. For a large problem it would be necessary to write the data to disk at this stage. persist forces the calculation
of the data which can take a few minutes.
[6]:
#PYTEST_VALIDATE_IGNORE_OUTPUT
x_data
[6]:
|
[7]:
#PYTEST_VALIDATE_IGNORE_OUTPUT
y_data
[7]:
|
The array x_data contains the microstructure information and has the dimensions of (n_samples, Nx, Ny). The array y_data contains the average stress value for each of the microstructures and has dimensions of (n_samples,). They are each chunked with 200 chunks for parallel computation.
View Microstructures¶
The microstructures are plotted using the plot_microstructures function. This function takes and number of microstructures and plots them to the screen using a specified color map.
[8]:
plot_microstructures(*x_data[:10], cmap='gray', colorbar=False);

Four of the six microstructures have grains that are elongated while the other two have equiaxial grains with varying average sizes
The following is a sample of the stress values, which have already been computed.
[9]:
#PYTEST_VALIDATE_IGNORE_OUTPUT
print('Stress Values', y_data[:10].compute())
Stress Values [0.2410227 0.25177921 0.24742908 0.24310681 0.2404942 0.23918413
0.24553951 0.24478376 0.24112834 0.2432467 ]
Now that the datasets are evaluated a homogenization workflow can be constructed to predict stress values for new microstructures.
Homogenization Workflow¶
The homogenization pipeline presented in this notebook takes in a dataset and
- calculates the 2-point statistics
- performs dimensionality reduction using Prinicple Component Analysis (PCA)
- and fits a polynomial regression model model to the low-dimensional representation.
This workflow has been shown to accurately predict effective properties in several examples [2][3], and requires the specification of the number of components used in dimensionality reduction and the order of the polynomial we will be using for the polynomial regression. This example shows how to use tools from Scikit-learn to try and optimize our selection for these two hyper-parameters.
Modeling¶
To create the homogenization workflow the steps used pipeline need to be defined. For this particular example, there are only 2 discrete phases and so the PrimitiveTransformer is appropriate. The statistical representation of the discretized microstructures is generated using the TwoPointCorrelation class. The data is then flattened from a 2-dimensional statistical representation to 1 dimension followed by a PCA step and then a polynomial regression step to develop the desired
structure-property linkage.
Note (issue or bug)¶
There are currently two issues with the pipeline.
- The
svd_solver='full'argument is required in the pipeline as the results are not correct without it. This might be an issue with Dask’s PCA algorithms and needs further investigation. - Dask’s
LinearRegressionmodule does not seem to solve this problem correctly and gives very different results to Sklearn’s. Needs further investigation
[10]:
pca_steps = [
("reshape", GenericTransformer(
lambda x: x.reshape(x.shape[0], x_data.shape[1], x_data.shape[2])
)),
("discritize",PrimitiveTransformer(n_state=2, min_=0.0, max_=1.0)),
("correlations",TwoPointCorrelation(periodic_boundary=True, cutoff=10,correlations=[(1,1),(0,0)])),
('flatten', GenericTransformer(lambda x: x.reshape(x.shape[0], -1))),
("pca", IncrementalPCA(svd_solver='full',n_components=40))
]
parallel_steps = pca_steps + [("poly", PolynomialFeatures())]
serial_steps = [("regressor", LinearRegression(normalize=False))]
The complete pipeline, pipeline, with all the steps is used for the final predictions. The pca_pipeline is used to observe the variance versus n_components. The parallel_pipeline removes the final step which is in serial to demonstrate the task graph.
[11]:
pipeline = Pipeline(parallel_steps + serial_steps)
pca_pipeline = Pipeline(pca_steps)
parallel_pipeline = Pipeline(parallel_steps)
Visualize the task graph¶
The pipeline results in an entirely lazy calulation. The task graph can be viewed to check that it remains parallel and doesn’t gather all the data. The calculation has not been evaluated yet, since the graph is generated with only a small part of the data.
Note (issue or bug)¶
Note that for some reason the y_data passed into fit is required to be a Numpy array and doens’t work with a correctly chunked Dask array, see the github issue.
[12]:
#PYTEST_VALIDATE_IGNORE_OUTPUT
parallel_pipeline.fit(x_data).transform(x_data).visualize()
[12]:

Observing variance changes with components¶
To start with, the variance changes are observed as a function of the number of components. In general for SVD as well as PCA the amount of variance captured in each component decreases as the component number increases. This means that as the number of components used in the dimensionality reduction increases the percentage of the variance will asymptotically approach 100%. This will be checked below
[13]:
pca_pipeline.fit(x_data).transform(x_data)
variance = pca_pipeline.named_steps['pca'].explained_variance_ratio_
n_components = len(variance)
Plot the cumulative variance changes versus number of components.
[14]:
n_components = len(variance)
plt.plot(
range(1, n_components + 1),
np.cumsum(variance * 100),
'o-',
color='#1a9641',
linewidth=2
)
plt.xlabel('Number of Components', fontsize=15)
plt.xlim(0, n_components + 1)
plt.ylabel('Percent Variance', fontsize=15)
plt.show()
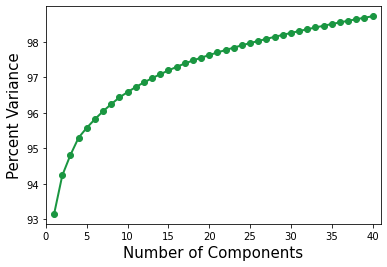
Over 95 percent of the variance is captured with the first 5 components. This means that the model may only need a few components to predict the average stress.
Optimize hyper-parameters¶
This section optimizes the number of components and the polynomial order by splitting the data into test and training sets using the train_test_spilt function.
[15]:
x_train, x_test, y_train, y_test = train_test_split(x_data.reshape(x_data.shape[0], -1), y_data,
test_size=0.2, random_state=3)
[16]:
x_train=x_train.reshape(x_train.shape[0],21,21)
[17]:
#PYTEST_VALIDATE_IGNORE_OUTPUT
GenericTransformer(lambda x: x.reshape(x.shape[0], 21, 21)).transform(x_train)
[17]:
|
The component count and polynomial order is optimized using cross-validation via GridSeachCV.
A dictionary of possible parameters, params_to_tune is passed to GridSearchCV. n_components varies from 1 to 11 and degree varies from 1 to 3.
[18]:
params_to_tune = {'pca__n_components': np.arange(1, 11),'poly__degree': np.arange(1, 4)}
grid_search = GridSearchCV(pipeline, params_to_tune).fit(x_train, y_train)
GridSearchCV stores the hyper-parameters that supply the best fit.
[19]:
#PYTEST_VALIDATE_IGNORE_OUTPUT
print('GridSearchCV.best_params_')
print('degree:', grid_search.best_params_.get('poly__degree'))
print('n_components:', grid_search.best_params_.get('pca__n_components'))
GridSearchCV.best_params_
degree: 2
n_components: 10
[20]:
assert(2 <= grid_search.best_params_.get('poly__degree') <= 3)
assert(3 <= grid_search.best_params_.get('pca__n_components') <= 12)
In the above the best degree order varies between 2 and 3 and the number of components between 6 and 12
The following plots R-squared vs Number of PC components plot for degree 1, 2 and 3 polynomials.
[21]:
def plot_line(x, mean, std_dev, color, label):
plt.fill_between(x, mean - std_dev, mean + std_dev, alpha=0.1, color=color)
plt.plot(x, mean, 'o-', color=color, label=label, linewidth=2)
def plot(dfs):
[plot_line(df_.n_comp.astype(int), df_.mean_, df_.std_, df_.color.iloc[0], df_.label.iloc[0]) for df_ in dfs]
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.,fontsize=15)
plt.ticklabel_format(style='sci', axis='y')
plt.ylabel('R-Squared', fontsize=20)
plt.xlabel('Number of Components', fontsize=20)
plt.show()
def add_labels(df):
return df.assign(
label=df.degree.map(lambda n: {1: '1st Order', 2: '2nd Order', 3: '3rd Order'}[n]),
color=df.degree.map(lambda n: {1: '#1a9850', 2: '#f46d43', 3: '#1f78b4'}[n]),
)
def rename(df):
return df.rename(
dict(
param_poly__degree='degree',
param_pca__n_components='n_comp',
mean_test_score='mean_',
std_test_score='std_',
),
axis=1
)
def groupby(df, col):
gb = df.groupby(col)
return [gb.get_group(x) for x in gb.groups]
df = groupby(
add_labels(
rename(
pandas.DataFrame(grid_search.cv_results_)
)
),
'degree'
)
plot(df)
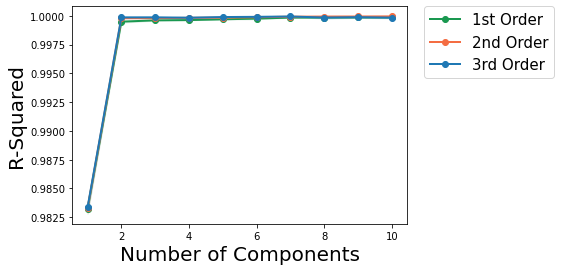
Use the best model from the grid scores.
[22]:
model = grid_search.best_estimator_
Check the low-dimensional representation¶
Check if the low-dimensional representation of the new data is similar to the low-dimensional representation of the train data by visualizing the microstructures in PC space.
[23]:
pca_pipeline.set_params(pca__n_components=3);
[24]:
x_trans_train = pca_pipeline.fit(x_train).transform(x_train).compute()
x_trans_test = pca_pipeline.transform(x_test).compute()
[25]:
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.set_xlabel('Component 1', fontsize=12)
ax.set_ylabel('Component 2', fontsize=12)
ax.set_zlabel('Component 3', fontsize=12)
ax.plot(*x_trans_train.T, 'o', label='Training Data', color='#1a9850')
ax.plot(*x_trans_test.T, 'o', label='Testing Data', color='#f46d43')
plt.title('Low Dimensional Representation', fontsize=15)
plt.legend(loc=1, borderaxespad=0., fontsize=15)
plt.legend(bbox_to_anchor=(1.05, 1.0), loc=2, borderaxespad=0., fontsize=15)
plt.show()
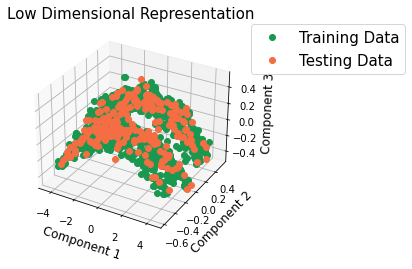
Prediction using Homogenization Pipeline¶
The n_components and degree parameters have been selected above so the model can now be used for a prediction
Note (issue or bug)¶
For some reason the y_data passed into fit is required to be a Numpy array and doens’t work with a correctly chunked Dask array, see the github issue.
[26]:
model.fit(x_train, np.array(y_train));
[27]:
y_predict = model.predict(x_test)
[28]:
y_train_predict = model.predict(x_train)
[29]:
#PYTEST_VALIDATE_IGNORE_OUTPUT
#assert (np.allclose(model.score(x_test, y_test), 1, rtol=1e-2))
print("R-squared %.5f" % model.score(x_test, y_test))
R-squared 0.99992
View one actual and predicted stress value for each of the 6 microstructure types to see how they compare.
[30]:
#PYTEST_VALIDATE_IGNORE_OUTPUT
print('Actual Stress ', y_test[::20].compute())
print('Predicted Stress', y_predict[::20])
Actual Stress [0.24747419 0.23720516 0.23682744 0.23797395 0.24410237 0.23981061
0.2491836 0.24560905 0.24318634 0.24148256 0.24681201 0.23985281]
Predicted Stress [0.24749071 0.23727036 0.23692804 0.23798497 0.24415089 0.23975951
0.2491645 0.24561821 0.24317014 0.2415227 0.24684247 0.23981962]
Lastly, evaluate our prediction by looking at a parity plot.
[31]:
fit_data = np.array([y_train.compute(), y_train_predict])
pred_data = np.array([y_test.compute(), y_predict])
y_total = np.concatenate((fit_data, pred_data), axis=-1)
line = np.min(y_total), np.max(y_total)
plt.plot(fit_data[0], fit_data[1], 'o', color='#1a9850', label='Training Data')
plt.plot(pred_data[0], pred_data[1], 'o', color='#f46d43', label='Testing Data')
plt.plot(line, line, '-', linewidth=3, color='#000000')
plt.title('Parity Plot', fontsize=20)
plt.xlabel('Actual', fontsize=18)
plt.ylabel('Predicted', fontsize=18)
plt.legend(loc=2, fontsize=15)
plt.show()
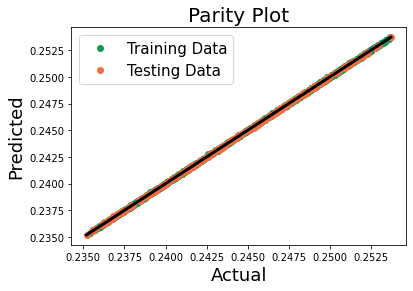
The pipeline is a good homogenization linkage for the effective stiffness for the 6 different microstructures and has predicted the average stress values for our new microstructures reasonably well.
References¶
[1] Landi, G., S.R. Niezgoda, S.R. Kalidindi, Multi-scale modeling of elastic response of three-dimensional voxel-based microstructure datasets using novel DFT-based knowledge systems. Acta Materialia, 2009. 58 (7): p. 2716-2725 doi:10.1016/j.actamat.2010.01.007.
[2] Çeçen, A., et al. “A data-driven approach to establishing microstructure–property relationships in porous transport layers of polymer electrolyte fuel cells.” Journal of Power Sources 245 (2014): 144-153. doi:10.1016/j.jpowsour.2013.06.100
[3] Deshpande, P. D., et al. “Application of Statistical and Machine Learning Techniques for Correlating Properties to Composition and Manufacturing Processes of Steels.” 2 World Congress on Integrated Computational Materials Engineering. John Wiley & Sons, Inc. doi:10.1002/9781118767061.ch25
[ ]: